
The Scandal at Kaggle

As I write these words, I marvel at my silver medal from the 2024 Automated Essay Scoring competition on Kaggle. This competition will go down in the annals of Data Science competitions as the equivalent of the French parliamentary election of 2024.
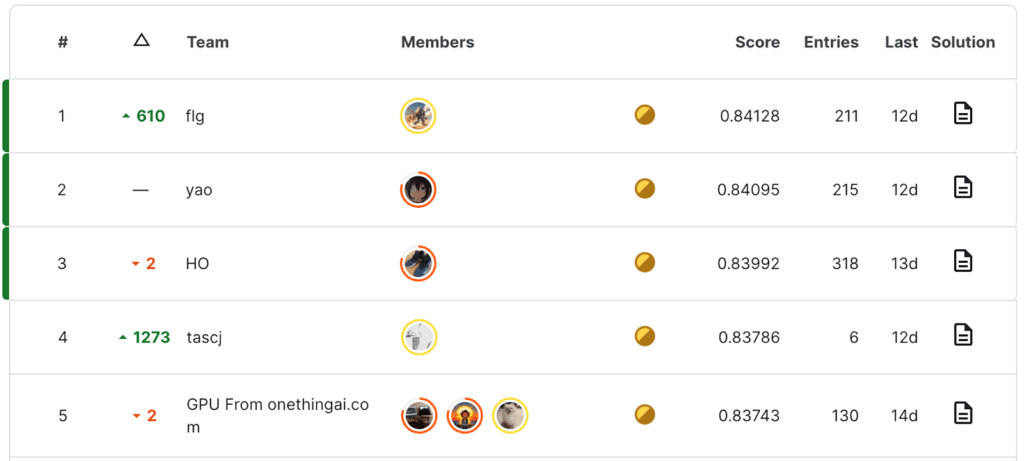
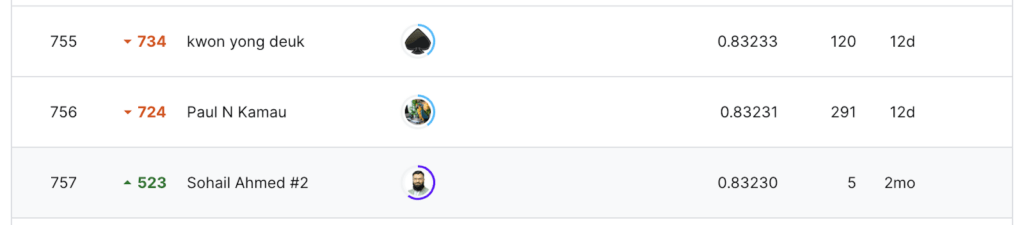
When the final rankings were published, the positions of the vast majority of participants were completely upended. Most top 20 participants dropped hundreds of positions down, and many mid-tier participants surged to the top of the rankings, myself included (I ended up placing 110th out of 2700 teams). My silver medal is mostly undeserved, but there are valuable lessons in what happened, applicable to real-life ML tasks, and that’s what this blog is about.

Silver Medal placement in the AES 2.0 Kaggle Competition
The competition’s goal was to develop a system to grade English language essays on a scale between 1 and 6. The competition’s sponsors (the Learning Agency Lab at Vanderbilt University, the Bill & Melinda Gates Foundation, Schmidt Futures, and the Chan Zuckerberg Initiative) were looking for an automated grading system that would reduce the expense and time required to hand-grade these essays. It would also allow students to receive regular and timely feedback on their writing. Imagine a system that works like Grammarly and can improve your emails, slack messages, and, yes, this blog, available for free to all.
Sponsored to the tune of $50,000 in prizes, the competition attracted ~3300 participants organized into ~2700 teams. As one of these participants, I had the chance to observe how the community collaborated to exchange ideas and educate first-timers. As is customary in Kaggle competitions, after their final rankings were announced, the top teams published their analysis of what worked and what did not, and I used these writeups, together with my own observations to come up with 5 main lessons from this dramatic competition.
But before I share these 5 lessons, let me explain a few important things.
Public Training data / Private Test Data: In this competition, the organizers publicly shared a training dataset of about 17,000 English-language essays, but kept their test dataset (rumored to be around 8000 essays) private. Furthermore, they divided this private test dataset into:
1/3rd used for continuously scoring submissions (every participant was allowed up to 5 submissions per day, and many submitted hundreds of submissions over the course of the competition. I submitted about 70). While the actual test essays were never published, the scores of submissions based on these test essays were published on something called the Public Leaderboard. These scores were used by participants to evaluate whether they were on the right path and making improvements.
2/3rds of the test data was held until the very end, to run the final scoring and ranking on the Private Leaderboard. While the smaller test dataset (the first 1/3rd) was indirectly accessible to users via so-called “probing”, the larger, (truly-private) test dataset was a complete mystery until the very end. Btw, this larger test dataset was the one that completely upended the rankings, in a phenomenon known on Kaggle as a “shake-down”.
Submission Scores: Each submission was evaluated on a metric called Quadratic Weighted Kappa (QWK). This metric looks at predicted labels and the true labels, and calculates a level of agreement between the two (how well the predicted labels match the true labels). This metric is similar to a simple percent agreement calculation, but is more robust against the predictions and true values being the same by chance.
The important thing to remember here is that the maximum score a submission could have achieved would be 1.0. Of course, no submission was as good as a 1.0. The winning submission had a QWK score of 0.84128, the cut-off for Gold Medals was 0.83583 and I had a score of 0.83523 (yes, only 0.0006 apart from Gold, not that I would have deserved it).
Now, let’s get back to our top 5 learnings.
1. The Importance of Good Data and Data Provenance
The best teams realized (through Exploratory Data Analysis) that training data was sourced from two places (dataset A – about 75% of test data, came from Persuade Corpus 2.0, and dataset B – another 25% – appeared to be entirely new and never used before this competition). The #4 participant in this competition, Tascj, theorized that “the scores from the two data sources are collected in different ways, thus not compatible”.

Another big finding was that the “truly-private” test dataset used for final rankings was more similar to the non-Persuade dataset B. Effectively, our training dataset has some data that looked like test data, and some data that was different from test data. The 1st ranked submission even “fixed” the scores of the Persuade-based dataset A in a technique called “pseudo labeling”. Many top submissions (1st, 2nd, 3rd, 5th) ended up dividing their training into two steps, pre-training on the Persuade dataset A, and fine-tuning on the B dataset. Other submissions used the source of data as a predictive feature (4th).
Insight: If you work in a corporate setting, you will most probably recognize the problem and possible solutions. Knowing where the data came from, having a catalog of data sources with metadata on creators, would save you several months of EDA and guessing. In this competition, this information made the difference between being in the top 5% and top 0.5%.
2. Knowing when to stop prevented overfitting
Data exploration led to the discovery of the two subsets of data. But this was not the only finding. It turned out that the Persuade subset of data consisted of essays on 7 topics, such as “Car-free cities” and “Does the electoral college work?”. Many top performing competition participants spent the final month of the competition trying to determine the topic of the essay based on its text, and use it as a predictive feature. They probed the private test dataset by dozens of submissions trying to determine if the test dataset contained any new topics.
As it turned out, this was not the case, and the private test data was not from the Persuade dataset, but the damage was done. A lot of participants over-optimized their models for the Persuade data by clustering the essays in groups that represented those 7 essay topics. When their models were applied to the “truly-private” test dataset, they underperformed and teams were “shaken-down” by hundreds of positions on the Private Leaderboard.
Former mid-tier-ranked participants surging to the top
Former top 50 dropping hundreds of ranks down
3. No Single Model (Compound AI Systems)
All well-performing submissions, with few exceptions, used the ensemble approach, where multiple models were combined to produce a composite prediction. No single LLM placed in the top 1% of this competition. But LLMs were definitely used as part of the model ensembles (the Deberta v3 LLM turned out to be a very popular choice).
How the outputs of individual models were combined ranged from simple weights to techniques such as stacking. Even the “good enough” model (see Learning #4) that guaranteed a top 5% ranking was an ensemble of 2 Gradient Boosted Trees models.
Insight: Considering all the data prep and transformations steps in-between, all top submissions were effectively Compound AI Systems. This is a new idea that is enabled by unified data and AI platforms, where one can put together multiple data processing steps and AI training or inference tasks into a graph of interacting components.

Read up on an example of a Compound AI System in my previous blog.
4. Gradient Boosted Decision Trees were Good Enough
The approach that got you into the top 5% of submissions (silver medal territory) was based on gradient boosted decision trees (GBDT), something the Data Science community was crazy about 5-10 years ago. About two weeks into the competition yukiZ, a Kaggle Expert from Tokyo, Japan, shared a notebook implementing a simple ensemble of two GBDT models – a LightGBM and a XGBoost model. That notebook, and derivative notebooks (especially the one from Prem Chotepanit), ended up scoring 0.83518+ – enough to place in the top 5%.

The “Good Enough” approach calculated tens of thousands of features based on paragraphs, sentences, and words of the essays. It then selected 13,000 most relevant features and used them to make predictions. LLMs were used in this approach, but only to calculate 6 features representing the probability of being the right essay score (1 to 6). These features, btw, ended up being some of the most predictive ones. Other predictive features were sentence and paragraph-level stats like number of errors in words, number of short and long sentences and paragraphs, number of short and long words (representing syntax knowledge and writing conventions). The rest of the 13K features were occurrences of particular words (representing the breadth of the vocabulary of essay writers).
Since this approach was entirely independent of the Persuade/non-Persuade test dataset fiasco, it handled the switch to previously-unseen test data rather well.
5. Collaboration UX
What made this competition so addictive and fun were 1) people and 2) the Kaggle UX. Chris Deotte, a data scientist at Nvidia, deserves a special call out. He shared countless notebooks with new ideas and answered dozens of questions from folks who were just starting out. Unfortunately for Chris, the “shake-down” in the final scoring of the submissions (see Learning #2) affected him similarly to other top participants, but he promised to continue sharing and helping in future competitions. Fingers crossed.

Since I am working on compute options for Data Science teams in my day-to-day job at Databricks, I paid attention to the Kaggle UX. It was largely conducive to a fun learning and competitive environment, with some exceptions:
Collaboration in Kaggle is done mostly by cloning Notebooks and sharing Datasets. Users start discussions and share their notebooks that then get cloned and improved by others.
There is a lot of bad notebook code out there, and Kaggle does not help with refactoring of it. Notebooks get cloned many many times, code gets modified, and by clone #99 the notebook is full of code cells from various other notebooks, and training and inference code jammed into one notebook, and controlled by variables. Ease of collaboration is important, but so is readability of code.
In modern data platforms notebook sharing and collaboration is a common feature. As far as I know, no platform allows smart editing of the same notebook by multiple contributors that actually results in an easily readable artifact. Take note, Databricks, Snowflake, and all you Jupyter clones!
I saw almost no usage of the Models artifact. Instead, users create file snapshots of their models (sometimes as pickled objects), and make Datasets out of them. These model-datasets are then imported by other users as files and loaded into memory using the joblib or dill libraries. Presumably, if users were encouraged to share their models as Models (via API calls) instead of pickled objects, the code would be a bit easier to read.
Insights: In future collaborative platforms I see teams submitting PRs against notebooks, instead of cloning them. The PRs would be reviewed by the original notebook author and the creator of the PR would get credited by points if the PR were approved. This would improve readability of code, and prevent situations where random participants gain strong positions in the leaderboard just by cloning a good publicly shared notebook.
What’s next, you ask?
Have I mentioned that Kaggle is addictive? There is a new top competition on Kaggle – the ARC Prize – and I intend to participate and get some AGI-“achieving” done. Expect a new report in a few months.