
Predicting user engagement with news on Reddit using Kaggle or Colab

About a month ago I wrote a 3-part blog series (parts 1, 2, and 3) on predicting user engagement with news in Reddit communities (subreddits). The Jupyter notebook that was the basis of that research is now available as a Kaggle kernel, together with the companion dataset.
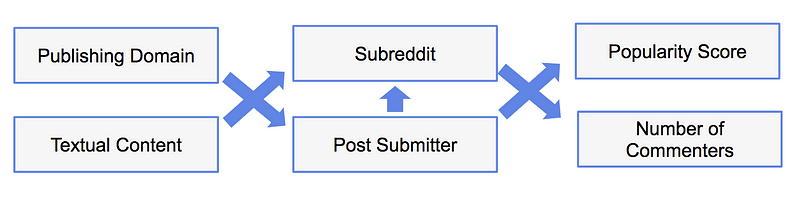
What I found was that the Publishing Domain and the Textual Content of a news article were good predictors of the Subreddit where a news article would end up at, as well as of the person who would share the news post. Furthermore, when used together, the Publishing Domain, Textual Content, and Submitter yielded a model that predicted the Subreddit with a 92% accuracy — something that could be used for anomaly detection, e.g. validating whether a posting to a Subreddit fits already seen behavior or constitutes a new trend or potentially a bot activity.
For user engagement metrics such as the Popularity Score or the Number of Commenters and Comments, the best predictors were the person who posted the article to Reddit (Post Submitter), and the Subreddit where the news was posted in. Models that used the Textual Content of the article did not have the best accuracy for predicting engagement metrics (whereas they were very predictive for Subreddit and Submitter), but I am currently working on improving the text embeddings I used and hope to publish more on this in the near future.
With the notebook now checked in github and shared in Kaggle, you can reproduce the results of the research much easier than before. Here are some tips and tricks for running the notebook in these environments.
Optimizing the notebook execution for the hosting environment
You can run this notebook either in Colab or in Kaggle. To run it in Colab, download the RedditEngagement notebook from github, import it into Colab, and set the current_run_in_colab variable to True in the “Define Constants and Global Variables” code cell, otherwise, set it to False.
You can choose between BigQuery and CSV files for the input dataset
Decide if you want to get the training data from the datancoffee BigQuery dataset or from snapshot CSV files. At present time only Colab allows you accessing the datancoffee BigQuery dataset. To get training data from BigQuery, set the current_read_from_bq variable to True in the “Define Constants and Global Variables” code cell, otherwise, set it to False.
Getting CSV files
Download the reddit-ds.zip snapshot file archive from the Dataflow Opinion Analysis github repository. Instructions for setting up the dataset are available in the notebook itself. In Kaggle, the snapshot dataset is packaged with the kernel. You don’t have to do anything to use it.
Run in Kaggle with GPUs
Running with GPUs really makes the difference in execution time. Training runs with GPUs are ~20s vs. ~400s with regular CPUs.
Improving model accuracy
The number of data points in the full Reddit dataset is large, so the size of available memory is important. The current_sample_frac variable controls the fraction of the input dataset that will be sampled and then divided in training, test and validation subsets. The default settings in the notebook have been selected to run in the publicly hosted versions of Kaggle and Colab. For SubredditClassification goal the setting is current_sample_frac = 0.5 and for the CommentsClassification goal the setting is current_sample_frac = 0.25.
Note that this is about half of what we used in our 3-part blog series and so the accuracy numbers you will get when running the notebook unmodified will be lower than what we have in our blog series.
Kaggle gives 6.5GB of memory when running with GPUs. To run the model with more accuracy, self-host the model in an environment with ~35–40GB of available memory. In this case you can set current_sample_frac = 0.99 for SubredditClassification and current_sample_frac = 0.5 (or higher) for CommentsClassification.
Enjoy and happy deep learning!